- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
语音转写产品较重心的优点在于较好的效率提升,彻底改变传统人工记录的低效模式。传统人工记录会议、采访或课程内容时,不需全程专注避免遗漏,后续整理还需逐句核对、补全信息,1 小时的语音内容往往需要 3-4 小时才能整理成完整文字;而语音转写产品可实现 “语音结束即出文字”,1 小时语音较快 5 分钟内完成转写,且支持实时转写模式,会议或课程进行中就能同步生成文字记录,会后无需额外整理,直接导出可用文档。这种效率优势让使用者从繁琐的记录工作中解放,将更多时间投入到内容分析、思考决策等重心事务中,尤其适合高频处理语音信息的职场人、教育工作者与创作者。语音转写技术能将方言语音准确地转写成对应的文字,保留地域特色。长沙法院语音转写系统

对于学习而言,智能语音转写是一个强大的助力工具.在语言学习方面,它可以让学生听到标准的发音并进行转写,通过对比自己的发音与转写结果的差异,及时发现并纠正语音问题,从而更有效地提高口语表达能力.在其他学科的学习中,学生可以利用语音转写将老师在课堂上的讲解快速转化为文字,在课后可以针对这些笔记进行复习和总结.而且,对于一些视觉学习效果较差的学生,语音转写提供的文字资料也更符合他们的学习习惯.此外,在准备演讲、考试等场景中,智能语音转写还能帮助学生对口述内容进行反复修改和完善,提升表达的准确性和逻辑性.长沙文字识别语音转写哪家好儿童教育版语音转写含发音评测,标注不准词汇并提供标准读音示范。

尽管智能语音转写技术取得了明显的发展,但仍然面临着一些挑战.其中一个主要的挑战就是不同口音和方言的识别.世界上存在着繁多复杂的口音和方言,即使是一些主流的智能语音转写系统,对于某些小众或地域性很强的口音也可能会出现识别不准确的情况.此外,同音异形字和多义词的处理也是一个难题.例如,“银行”和“行走”的“行”字,在语音转写时如何准确判断使用者想要表达的正确用字,需要强大的语义理解能力.另外,隐私和数据安全也是智能语音转写面临的问题.由于语音转写涉及用户的语音内容,这些内容可能包含个人隐私信息,如何确保这些信息在转写和存储过程中的安全性,防止信息泄露,是技术开发和相关法律法规需要共同应对的挑战.
为应对日益严格的数据安全需求,语音转写产品推出多层级安全加固方案。在数据存储层面,采用 “分布式加密存储” 技术,将语音与转写数据拆分存储在不同服务器,每段数据均通过 AES-256 加密算法保护,即使单服务器数据泄露也无法还原完整信息;在访问控制层面,新增 “多因子认证 + 动态权限” 机制,用户登录需验证密码 + 手机验证码,同时根据使用场景动态调整权限,如异地登录时开放查看权限,禁止导出数据;在数据销毁层面,支持 “定时自动销毁 + 手动长久删除”,用户可设置数据留存期限(如 7 天、30 天),到期自动彻底销毁,手动删除时采用 “多次覆写” 技术,防止数据被恢复,多方面保障用户语音与文字数据安全。语音转写的技能等级体系激励用户学习,升级后可解锁自定义模板等高级功能。

为满足残障用户需求,语音转写产品推出无障碍服务适配功能。针对视障用户,产品支持与屏幕阅读器深度兼容,转写过程中的操作提示、文字内容可通过语音播报同步输出,方便视障用户完成转写启停、文档保存等操作;针对听障用户,除实时语音转文字外,还支持 “文字转语音” 反向功能,听障用户输入文字后,系统可转化为清晰语音与他人沟通,同时转写内容可生成超大字体版本,适配听障用户阅读习惯;针对肢体残障用户,产品支持语音控制功能,用户通过 “开启转写”“导出文档” 等语音指令即可操作,无需手动点击,同时适配外接辅助设备(如定制键盘、摇杆),降低操作难度。这些无障碍适配让残障用户能便捷使用语音转写服务,享受科技带来的便利。多speaker分离功能让语音转写在多人对话场景中,能区分不同发言者身份。北京多角色语音转写软件系统
语音转写的多模态交互支持“语音+手写”,融合文字与图形生成完整文档。长沙法院语音转写系统
语音转写产品针对儿童教育场景,开发趣味化、引导式转写功能,适配儿童学习习惯。在亲子阅读场景,产品支持 “绘本语音转写 + 互动答问”,家长朗读绘本时,系统实时转写文字并同步显示绘本插图,转写完成后自动生成与内容相关的趣味问题(如 “小熊现在去了哪里呀”),帮助儿童加深内容理解;在口语练习场景,产品内置儿童发音评测模块,转写儿童英语、语文口语表达时,同步分析发音准确度、语调流畅度,生成可视化评分报告,标注 “发音不准词汇” 并提供标准读音示范,助力儿童提升口语能力;此外,产品还支持家长管控功能,可设置每日使用时长、内容过滤规则,避免儿童接触不适宜内容,打造安全的学习辅助环境。长沙法院语音转写系统
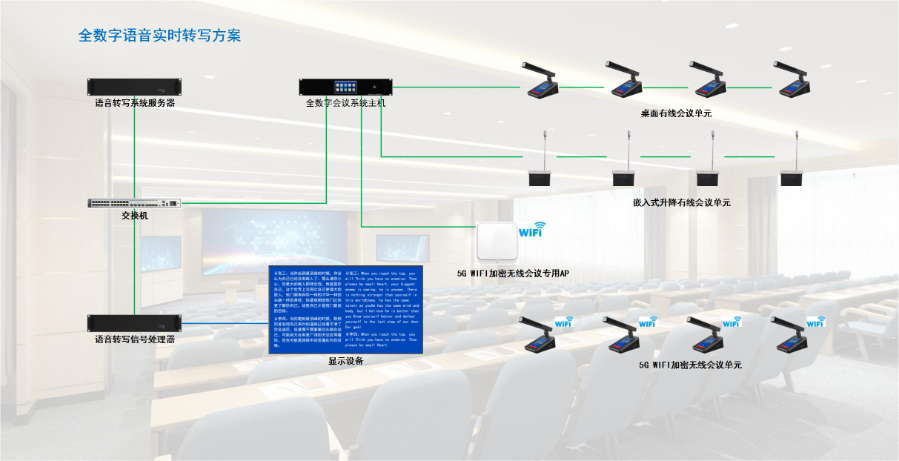
语音转写产品具备高度灵活的个性化定制能力,可根据个人、企业的专属需求调整功能与设置,满足差异化使用场景,这是其提升用户粘性的重要优点。个人用户层面,支持自定义词典功能,可添加行业术语、专属人名、生僻地名等,例如医生可导入 “心肌梗死、头孢哌酮” 等医学词汇,确保专业场景转写准确;还能自定义转写格式,如设置会议记录默认包含 “参会人、时间、议题” 等固定模块,无需每次手动排版。企业用户层面,可进行深度定制化开发,如对接企业内部 OA 系统,转写文档自动同步至员工工作台账;定制企业专属界面,添加企业 LOGO、重心功能快捷入口;设置权限管理体系,按部门、岗位分配转写文档查看与编辑权限,确保企业信息...
- 北京多语言识别语音转写作用 2026-04-30
- 自动翻译语音转写软件系统 2026-04-30
- 文字识别语音转写哪家好 2026-04-30
- 北京实时语音转写同时翻译 2026-04-30
- 南京智能翻译语音转写软件系统 2026-04-30
- 上海国产化语音转写报价 2026-03-14
- 角色分离语音转写售后 2026-03-14
- 智能语音转写价格 2026-03-14
- 广州语音转写作用 2026-03-14
- 南京实时语音转写售后 2026-03-14


- 庭审语音转写云平台 2026-03-14
- 长沙语音转写系统 2026-03-14
- 长沙多语言识别语音转写故障排除 2026-03-14
- 广州智能语音转写有什么功能 2026-03-14
- 上海会议纪要语音转写系统 2026-03-14
- 法院语音转写字幕 2026-03-13



- 南京智能翻译语音转写软件系统 04-30
- 广州国产化会议预约有什么功能 04-10
- 南京数字会议售后维护 04-10
- 上海5G WIFI数字会议语音转写 04-10
- 数字会议系统 04-10
- 广州5G WIFI数字会议价格 04-10
- 上海数字会议 04-10
- 北京同声传译数字会议报价 04-10
- 北京会议室管理会议预约报价 04-10
- 北京鹅颈数字会议语音转写 04-10