迭代化合物挑选过程如上所述,现在的方针是对界说为空间掩盖方针的类进行迭代,从每个类中挑选排名比较好的化合物样本,然后重复此循环屡次。一旦所有化合物均已按特点进行了排序并分配给不同类型的空间掩盖类别,而且已界说了每次迭代的较小簇巨细,则能够运转挑选算法以生成多样性网格2015挑选渠道和2019挑选渠道的比较图6(分子量)和图7(clogP)展现了2015年和2019年平板子集的特性曲线。2015年的挑选平板网格显现,MW<350Da的偏差很大,A和B类的clogP规模为1-3,使这些化合物简直呈碎片状。我们还发现,2015年筛查平板的A和B类命中率低于C类,即分子量和clogP规模受限会导致整个挑选的化合物多样性失衡。根据这些观察,我们决议更改2019版网格的排名标准:引入高溶解度和高渗透性作为A列的正挑选标准,而MW和clogP不再直接考虑。可是,为了同时取得杰出的浸透性和溶解性,较低的MW和clogP仍然是有利的。如图9和图10所示,与其他两列相比,2019版:高溶解度和浸透率色谱柱的MW和clogP散布已移至较低值。更重要的是,2019版的新设计还似乎对前两列和行中的化学起始点产生了积极影响。高通量筛选技能加速联合用药研讨。天然产物化合物库筛选
新药研制进程与本钱1、新药研讨与开发进程新药的发现在新药研讨和开发进程中占有非常重要的地位,包含:新药的发现、药物效果靶点(target)以及生物符号(biomarker)的挑选与确认;先导化合物(leadcompound)的确认;构效关系的研讨与活性化合物的挑选;候选药物(candidate)的选定;完结候选药物的选定后,新药研制进入临床前研讨,包含化学、制造和操控(ChemicalManufactureandControl,CMC)、药代动力学(Pharmacokinetics,PK)、安全性药理(SafetyPharmacology)、毒理研讨(Toxicology)、制剂开发等,顺畅的话将终究进入临床研讨、新药申请和同意上市阶段。中药复方筛选高通量筛选的不同使用场景。

目前已知氨基酸序列的蛋白质分子约有2.1亿个,但到RCSBPDB上录入的被实验解析的蛋白质三维结构只有18,1295个,不到蛋白质总数的0.1%。究其根本,通过X射线衍射、核磁共振或冷冻电镜等方法获得蛋白质三维结构,哪个不耗时费力、需要很多资金投入?另,计算机猜测蛋白质结构有诸多限制,SWISS-MODEL要求序列同源性>30%,I-TASSER要求序列能穿到现有结构,ROBETTA要求氨基酸序列<200。全国苦“蛋白质三维结构”久矣!直到AlphaFold2横空出世。AlphaFold2横空出世2020年底,AlphaFold2(DeepMind公司开发的AI程序)在CASP14(第14届蛋白质结构猜测竞赛)中将蛋白结构猜测准确性从40分提高到92.4分,完成了原子精度或者接近原子精度的结构猜测,震惊生物界。
化合物个别特点排名图4中展现了分配给2019挑选平台中化合物样品的一切正告标志的概述。依据表1中所述的特点,可以将化合物分为三个特点类别:由于“高溶解度和高渗透性”,上面的类别“高溶解度和渗透性”包含正符号的化合物;第二类“中性”包括一切没有负符号的化合物;一切剩下的带有一个或多个正告符号的化合物都被添加到“特点正告符号”类别中。在每个类别中,按照表1的定义应用优先级排序。生物活性和化学结构空间掩盖在对网格的X轴进行特点排名的情况下,咱们需要为拾取回合定义一种掩盖多样性的方法,以生成Y轴。咱们使用了几种分类方法,这些方法可以分为以下几类:单个生物靶标类、生物化合物轮廓空间类和化学空间掩盖类。高通量药物筛选的意义。
总结现在,2019年的挑选平台网格是NIBR根据平板多样性驱动的子集挑选的首要来源,它可用于50-100个子集挑选,每年在NIBR中有超过5万种化合物用于生化和细胞测验。二维多样性网格根据挑选化合物合集的要害特征:针对尽可能多的靶标的多样性掩盖规模以及根据需要搅扰靶标的恰当化合物特点。这种大小合适的化合物板组的网格为迭代和子集挑选供给了灵活性,然后允许根据分子特性以及化学和生物多样性标准选择板组。从2015年挑选平台获得的一项重要经验是,将溶解度和渗透性作为决议化合物是否有价值的首要决议因素,而不是MW和clogP规模。抗体药物都是怎么筛选出来的?分子对接 化合物筛选
化合物处理技能是让规划的筛选渠道作业的根底。天然产物化合物库筛选
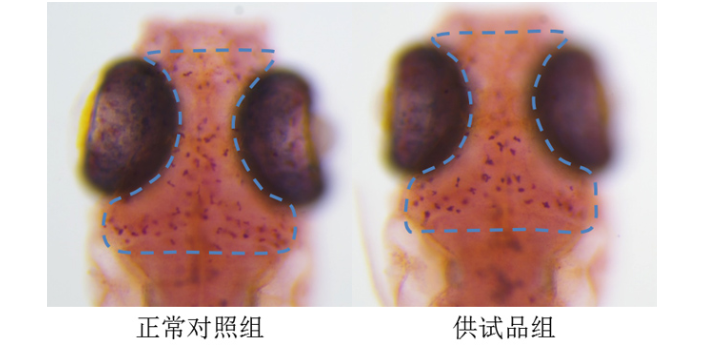
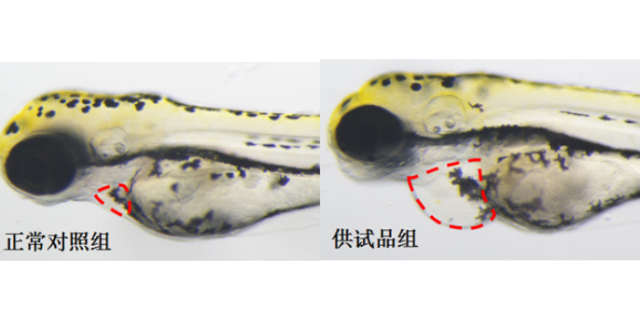
纤维性疾病简直影响到身体的每一个组织,这种疾病的产生和发展会迅速导致组织功能障碍、机体组织衰竭,导致逝世。成纤维细胞诱导细胞外基质(ECM)的大量沉积(I和V型胶原作为标志物)是纤维化疾病的标志。目前临床可供使用的抗纤维化的药物相对缺少。2021年,由MichaelGerckens等人开发了一种根据表型挑选开发新式抗纤维化药物的办法,并鉴定出一系列具有较高活性的抗纤维化化合物。挑选模型建立首要作者建立了一种深度学习模型(deeplearningmodel),可以对高通量显微成像取得的数千张细胞外基质(ECM)免疫染色图片进行批量分析,以确定具有改进纤维化状况的先导化合物。天然产物化合物库筛选