大有可为的噬菌体抗体库基于抗体基因序列来源,噬菌体抗体库分为三大类:天然抗体库(Naveantibodylibrary),基因来源人体或动物体内的血液、骨髓、脾脏和扁桃体内的B淋巴细胞。优点是可获得人抗体、针对所有天然抗原、库足够大,可直接获得高亲和力抗体,但建库耗时费力,而且存在很多未知和不可控因素。半合成抗体库(Semi-syntheticantibodylibrary)由人工合成的一部分可变区序列与另一部分天然序列组合构建而成的抗体库。其主要是使用种系的重链、轻链或重排的可变区片段,其中一个或多个CDR要随机重排。对难于在体内进行免疫的抗体研发具有良好的应用前景;怎么轻松批量筛选高质量动物细胞RNA?东北高通量化合物筛选

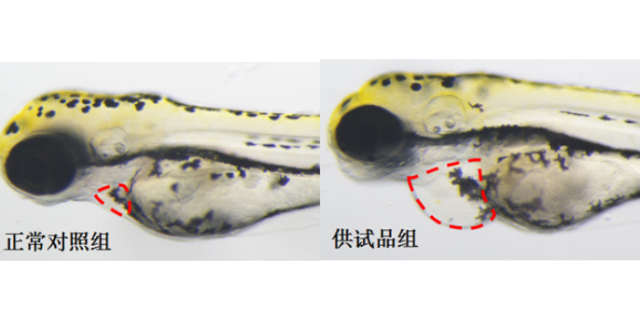
纤维性疾病简直影响到身体的每一个组织,这种疾病的产生和发展会迅速导致组织功能障碍、机体组织衰竭,导致逝世。成纤维细胞诱导细胞外基质(ECM)的大量沉积(I和V型胶原作为标志物)是纤维化疾病的标志。目前临床可供使用的抗纤维化的药物相对缺少。2021年,由MichaelGerckens等人开发了一种根据表型挑选开发新式抗纤维化药物的办法,并鉴定出一系列具有较高活性的抗纤维化化合物。挑选模型建立首要作者建立了一种深度学习模型(deeplearningmodel),可以对高通量显微成像取得的数千张细胞外基质(ECM)免疫染色图片进行批量分析,以确定具有改进纤维化状况的先导化合物。新药筛选实验药物筛选技能的研讨与使用。

为了规划具有比较大多样性和较好特点的子集,咱们开发了以下进程:给定一个已界说用于分层的化合物类别,以及基于多目标特点的排名,然后从每个类别中对比较好的排名的化合物进行抽样就得到具有比较好特点的子集,该子集能够满足有必要掩盖所有类别的约束条件。重复此进程,直到终究挑选了所有化合物,然后盯梢挑选化合物的挑选进程。终究,每种化合物具有两个相关的特点:特点等级和挑选该化合物的挑选回合。经过适当的装箱策略,能够将该2D空间划分为一个或多个板块,将它们堆叠成一个或多个板块,将2D网格划分为一组,然后使科学家能够从该网格中挑选用于检测的板块组。经过挑选与N个挑选回合中的一个回合相对应的网格单元,能够获得比较大掩盖范围的子集。经过集中在具有比较高功能等级的网格单元上,能够获得良好功能的子集。
化合物库作为药物挑选的重要东西,决定了小分子药物研制的速度和质量。作为全球有名的化合物供应商,MCE可提供活性化合物库、类药多样性库、虚拟挑选数据库等170余种化合物库,化合物总数约1600万,每种化合物均有翔实的生物活性数据和(或)明晰准确的理化结构信息。这些高质量化合物库可用于高通量挑选(HTS)、高内在挑选(HCS)、虚拟挑选(VS),是进行新药研制及新适应症探索的专业东西。•活性化合物库:可提供110+种即用型化合物库,包含20,000+种具有清晰报道的、活性已知、靶点清晰的小分子化合物及17,000+种片段化合物。抗体药物都是怎么筛选出来的?
抗体靶向疗法的临床使用越来越普遍,估计未来将有更多抗体药物进入市场。“工欲善其事,必先利其器”,在这抗体药物的“黄金时代”,如何经济高效的筛选到抗体药物,成为赢在起跑线上的关键所在。抗体多样性的来历抗体的实质是免疫球蛋白,指具有抗体活性或化学结构的球蛋白。抗体药物则是将特异性地针对某种疾病的抗体人源化改造后得到的靶向药物。抗体Y形的两个分叉顶端都有被称为互补位(抗原结合位)的锁状结构,该结构只针对一种特定的抗原表位。这就像一把钥匙只能开一把锁一般,使得一种抗体只能和其间一种抗原相结合。针对新药研发高通量筛选1小时究竟能挑选多少样品?东北高通量化合物筛选
虚拟筛选在药物发现中的意义。东北高通量化合物筛选
单个生物靶标类。有关单个生物靶标的生物活性数据是从咱们的内部系统“hithub”中提取的,该系统包含一切内部生物活性数据,并定期经过来自主要公共数据源(ChEMBL,ClarivateIntegrity,GOSTAR)的生物活性数据进行更新。生物化合物概括空间类。按单个靶标对化合物分组的一种补充方法是跨多个靶标或分析使用生物学谱数据。猜测配置文件是在单个目标基础上核算的,以依据pfam数据库中的蛋白质域注释取得贝叶斯活性指纹(BAFP)以及每个蛋白质家族来取得贝叶斯域指纹(BDFP)。化学空间掩盖类。NIBR开发了一种化合物骨架分类方法,称为“骨架树”,随后扩展到了“骨架网络”。该网络用于纯粹依据化学结构来界说类别。手动分类。以上一切分类都是经过核算得出的,还需要有依据化学家们的经验常识来指定的分类。东北高通量化合物筛选